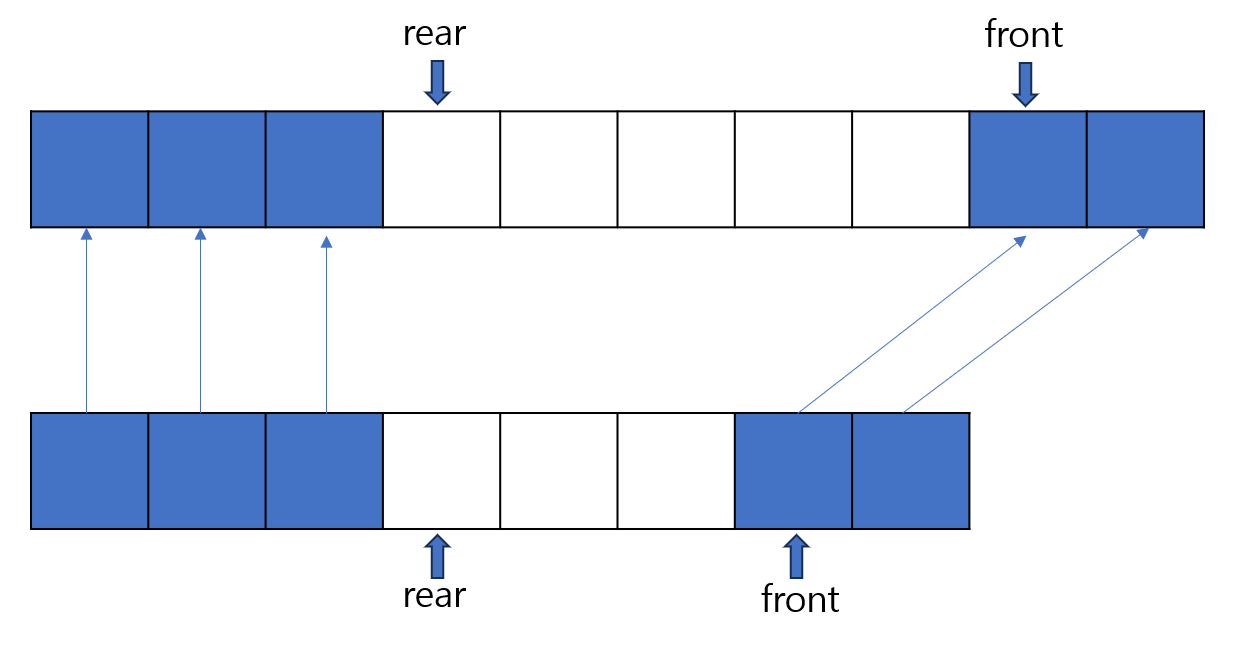
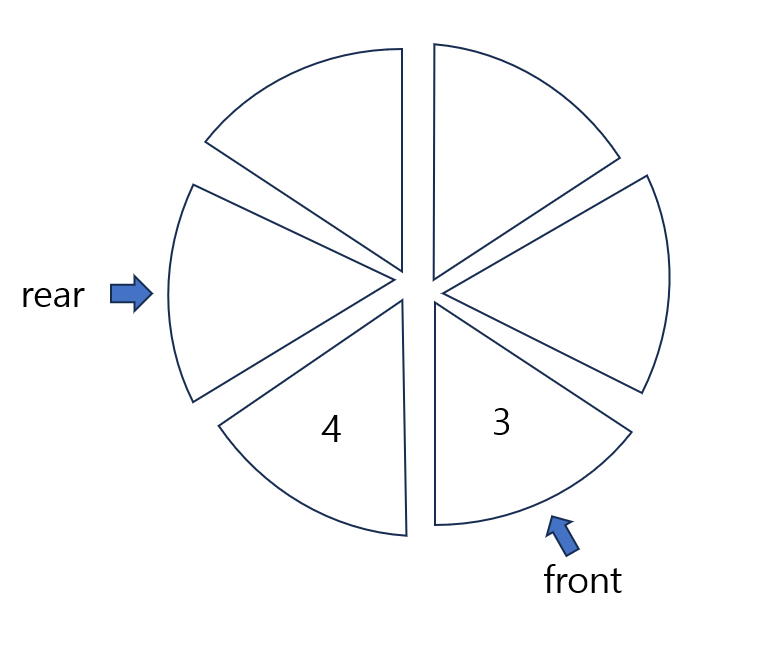
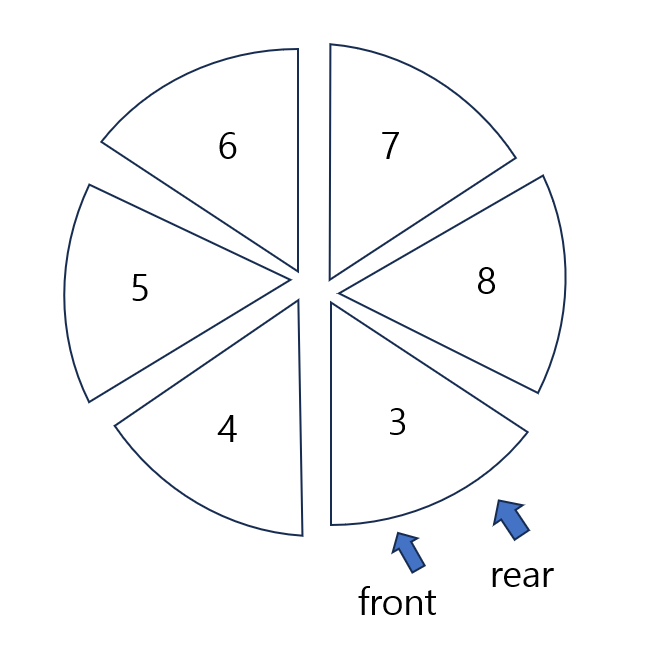
//가장 앞, 뒤의 데이터를 삭제합니다
const bool RemoveFront()
{
return Remove(head->next);
}
const bool RemoveBack()
{
return Remove(tail->prev);
}
private:
//데이터를 찾아서 삭제합니다
const bool Remove(Node* nd_remove)
{
if (size <= 0) return false;
nd_remove->prev->next = nd_remove->next;
nd_remove->next->prev = nd_remove->prev;
delete nd_remove;
--size;
return true;
}이전 포스팅에서 소개한 AddFront(),AddBack(),Add()와 동일한 구조의 함수다
Remove()는 성공과 실패를 리턴하고, 노드를 삭제하며 삭제된 노드 앞뒤의 노드끼리 연결시킨다
//원하는 데이터를 찾아서 삭제합니다
const bool RemoveData(const Data& data)
{
if (size <= 0) return false;
for (Node* nd = head->next; nd != tail; nd = nd->next)
{
if (nd->data == data)
{
//삭제할 데이터를 찾았습니다. 삭제합니다
return Remove(nd);
}
}
//삭제할 데이터를 찾지 못했습니다
return false;
}
//모든 데이터를 삭제합니다
void RemoveAll()
{
while (RemoveFront()) {}
}
RemoveData(): 동일한 데이터를 찾아 삭제.
RemoveAll(): 모든 데이터를 삭제.
RemoveData()에서 노드의 순회을 볼 수 있다.
head->next노드부터 시작해서 tail이 아닌 노드면 계속 순회한다.
역순회도 다르지 않다.
for (Node* nd = tail->prev; nd != head; nd = nd->prev)논리적으로 거꾸로 돌아가게 하면된다.
프로그래밍 처음 공부했을때 꽤 어려웠던 연결리스트였는데 지금 다시 보니까 구현자체는 어렵지 않았다.
데이터의 삽입,삭제시 노드연결만 신경써주면된다.
https://github.com/ForestBird1/MyContainer
GitHub - ForestBird1/MyContainer
Contribute to ForestBird1/MyContainer development by creating an account on GitHub.
github.com
'C++ 자료구조' 카테고리의 다른 글
| [C++] 나만의 DoubleLinkedList(이중연결리스트)만들기 (2) - 생성자, 데이터추가 (0) | 2023.08.29 |
|---|---|
| [C++] 나만의 DoubleLinkedList(이중연결리스트)만들기 (1) - 기초 (0) | 2023.08.28 |
| [C++] 나만의 Queue만들기 (4) - 동적 원형 큐 (0) | 2023.08.27 |
| [C++] 나만의 Queue만들기 (3) - 원형 큐 구현 (0) | 2023.08.27 |
| [C++] 나만의 Queue만들기 (2) - 원형 큐, 기초 (0) | 2023.08.27 |